
程式語言用來開發程式,程式用來處理和解決問題,無論使用C++或C#或Java等程式語言,程式設計的邏輯基本上是相通的。
假設要處理網路世界的安全性問題,首先,無論透過手機或電腦連接網路,每位使用者均以帳號密碼來確認自己獨一無二的身分,進而存取屬於個人的網路資源。為了安全考量,使用者輸入的帳號密碼,不能以原始的格式(明碼)儲存,而需以某種編碼後的結果存放在雲端空間,以降低駭客入侵雲端能直接取得使用者的帳密(明碼)的風險。
C++除了具備加減乘除的運算能力,還具備邏輯運算能力。邏輯運算的四個基本運算子為
& and
| or
^ xor
! not
電腦使用二進位數字系統,二進位只有 0 與 1,所以邏輯運算對電腦非常重要,0 與 1 的邏輯運算可以用真值表來表示
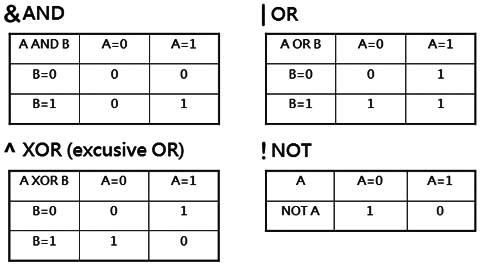
對 AND 運算來說,唯有 x y 均為 1 時,x AND y 才為"真"
對 OR 運算來說,只要 x 或 y 有一個為 1,x OR y 即為"真"
對 XOR 運算來說,當 x 和 y 不同時,x XOR y 才得到"真"
而 NOT 就和負號一樣,NOT 0 = 1,NOT 1 = 0
其中 XOR 運算具有可還原的特性,可以應用在編碼運算!
例如,以某個二進位數 10 來說,當它與另一數進行 xor 運算,例如與 11
10 XOR 11 = 01 ( 第一位 1 xor 1 = 0,第二位 0 xor 1 = 1)
用 01 這個結果,再和 11 進行 xor 運算一次
01 XOR 11 = 10 ( 第一位 0 xor 1 = 1,第二位 1 xor 1 = 0)
某數 a 與另一數 b 進行 xor 運算所產生的 c,雖然看起來和 a 不同,但只要以 c 再和 b 進行 一次 xor 運算,就可以重新得到 a,這就是最簡單的可還原編碼的一種方式,b 就是還原的 key!
#include <iostream>
class encoding
{
private:
int key[10]={ 8, 5, 2, 1, 4, 7, 6, 9, 0, 3 };
public:
void enc(int x[], int n) {
for(int i=0; i<n; i++)
x[i] = x[i] ^ key[i];
}
void dec(int x[], int n) {
for(int i=0; i<n; i++)
x[i] = x[i] ^ key[i];
}
void print(int x[], int n) {
for(int i=0; i<n; i++)
std::cout << x[i];
std::cout << std::endl;
}
};
int main()
{
int mypass[] = { 1, 3, 9, 4 };
encoding myenc;
myenc.enc( mypass, 4 );
std::cout << "編碼結果:";
myenc.print( mypass, 4 );
myenc.dec( mypass, 4 );
std::cout << "解碼:";
myenc.print( mypass, 4 );
return 0;
}
假設要處理網路世界的安全性問題,首先,無論透過手機或電腦連接網路,每位使用者均以帳號密碼來確認自己獨一無二的身分,進而存取屬於個人的網路資源。為了安全考量,使用者輸入的帳號密碼,不能以原始的格式(明碼)儲存,而需以某種編碼後的結果存放在雲端空間,以降低駭客入侵雲端能直接取得使用者的帳密(明碼)的風險。
C++除了具備加減乘除的運算能力,還具備邏輯運算能力。邏輯運算的四個基本運算子為
& and
| or
^ xor
! not
電腦使用二進位數字系統,二進位只有 0 與 1,所以邏輯運算對電腦非常重要,0 與 1 的邏輯運算可以用真值表來表示
對 OR 運算來說,只要 x 或 y 有一個為 1,x OR y 即為"真"
對 XOR 運算來說,當 x 和 y 不同時,x XOR y 才得到"真"
而 NOT 就和負號一樣,NOT 0 = 1,NOT 1 = 0
其中 XOR 運算具有可還原的特性,可以應用在編碼運算!
例如,以某個二進位數 10 來說,當它與另一數進行 xor 運算,例如與 11
10 XOR 11 = 01 ( 第一位 1 xor 1 = 0,第二位 0 xor 1 = 1)
用 01 這個結果,再和 11 進行 xor 運算一次
01 XOR 11 = 10 ( 第一位 0 xor 1 = 1,第二位 1 xor 1 = 0)
某數 a 與另一數 b 進行 xor 運算所產生的 c,雖然看起來和 a 不同,但只要以 c 再和 b 進行 一次 xor 運算,就可以重新得到 a,這就是最簡單的可還原編碼的一種方式,b 就是還原的 key!
#include <iostream>
class encoding
{
private:
int key[10]={ 8, 5, 2, 1, 4, 7, 6, 9, 0, 3 };
public:
void enc(int x[], int n) {
for(int i=0; i<n; i++)
x[i] = x[i] ^ key[i];
}
void dec(int x[], int n) {
for(int i=0; i<n; i++)
x[i] = x[i] ^ key[i];
}
void print(int x[], int n) {
for(int i=0; i<n; i++)
std::cout << x[i];
std::cout << std::endl;
}
};
int main()
{
int mypass[] = { 1, 3, 9, 4 };
encoding myenc;
myenc.enc( mypass, 4 );
std::cout << "編碼結果:";
myenc.print( mypass, 4 );
myenc.dec( mypass, 4 );
std::cout << "解碼:";
myenc.print( mypass, 4 );
return 0;
}
在 class encoding 中,enc() 函式與 dec() 函式完全相同,所以就算主程式的解碼部份改呼叫 enc() 函式,當然還是會得到正確的結果。事實上 XOR 運算在磁碟陣列的容錯設計上廣泛被採用,相當有實用價值。





